
这是一个数据结构和算法的动态可视化平台:
https://visualgo.net/zh
里面介绍了各种常见算法和数据结构的概念,还提供了可视化展示
这个仓库汇总了十大经典排序算法,还提供了各个算法的js代码展示
https://github.com/biaochenxuying/blog/issues/42
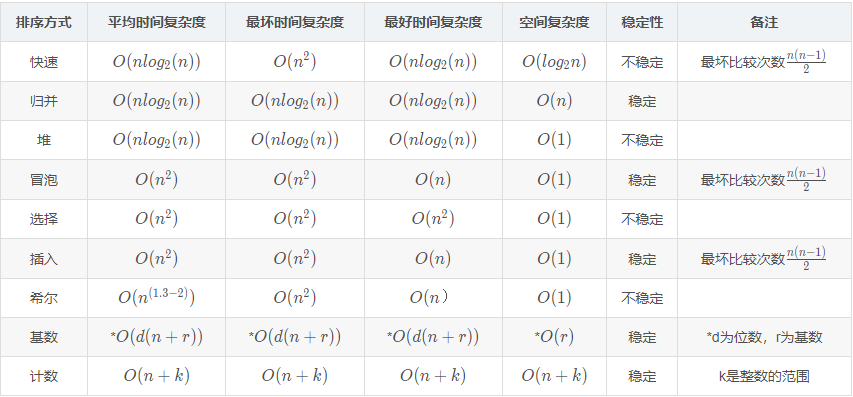
各种排序算法的时间复杂度:
这是一个数据结构和算法的动态可视化平台:
https://visualgo.net/zh
里面介绍了各种常见算法和数据结构的概念,还提供了可视化展示
这个仓库汇总了十大经典排序算法,还提供了各个算法的js代码展示
https://github.com/biaochenxuying/blog/issues/42
各种排序算法的时间复杂度:
目录
切换目录:
cd / 切换到根目录
cd /bin 切换到根目录下的bin目录
cd ../ 切换到上一级目录 或者使用命令:cd ..
cd ~ 切换到home目录
cd - 切换到上次访问的目录
cd xx 切换到本目录下的名为xx的文件目录,如果目录不存在报错
cd /xxx/xx/x 可以输入完整的路径,直接切换到目标目录,输入过程中可以使用tab键快速补全
mkdir 新增目录
ls 查看目录
rm doc 删除当前目录的doc文件
mv oldName newName 修改目录名
文件
touch 新增文件
rm doc 删除当前目录下的doc文件
查看文件:
cat a.txt 查看文件最后一屏内容
less a.txt PgUp向上翻页,PgDn向下翻页,”q”退出查看
more a.txt 显示百分比,回车查看下一行,空格查看下一页,”q”退出查看
tail -100 a.txt 查看文件的后100行,”Ctrl+C”退出查看
GMT时间格式转YYYY-MM-DD格式:
1 | function GMTToStr(time) { |
获取最近自定义天数的时间范围:
1 | function getRecentDays(days) { |
时间戳转正常格式时间:
1 | function timestampToTime(timestamp) { |
这篇博客未来会添加许多代码片段,对于一篇文章来说太长了,于是新建了一个git仓库,未来的js code snippets会更新在这个repo里:
https://github.com/Xutangxin/JS-code-snippets/blob/main/js%20code%20snippets.md
最近在开发中需要在前端页面导出Excel文件,最开始的实现方案本来是和后端同学配合,前端发送请求获取数据然后导出,后来发现这样的方案不能完全满足需求,原因是前端表单的一些特有的字段比如序号什么的也要导出,但是从后端传来的源数据是没有序号的,序号是前端页面加上的。所以后来还是选择了纯前端导出Excel文件的方案。
总体思路是通过html引入excel模板,再在html里放入表格内容(dom),然后转成blob文件流下载表格
实现表格导出的函数:
1 | export default function exportTable(table, exportName) { |
获取表格dom,我使用的框架是Vue,所以通过$refs来获取dom:
1 | let table = this.$refs.table.$el; |
传入参数到函数,就可以导出excel文件了:
1 | exportTable(table, tableName); |
之前学习JavaScript的过程中学习了正则表达式的基本使用,也做了一些笔记,但之后很少用到这些正则表达式的知识,所以也慢慢忘记了其基本使用。最近在开发中有遇到需要正则表达式的地方(主要是字符串匹配和替换),所以就把之前留下来的笔记整理了一下
more >>REST全称为Representational State Transfer,意思是表现层状态转移
根据百度百科的解释,RESTful指的是一组架构约束条件和原则,满足这些约束条件和原则的应用程序或设计就是 RESTful
Web 应用程序最重要的 REST 原则是,客户端和服务器之间的交互在请求之间是无状态的。从客户端到服务器的每个请求都必须包含理解请求所必需的信息。如果服务器在请求之间的任何时间点重启,客户端不会得到通知
在服务器端,应用程序状态和功能可以分为各种资源。资源是一个有趣的概念实体,它向客户端公开。资源的例子有:应用程序对象、数据库记录、算法等等。每个资源都使用URI得到一个唯一的地址。所有资源都共享统一的接口,以便在客户端和服务器之间传输状态。使用的是标准的 HTTP 方法,比如 GET、PUT、POST 和 DELETE
RESTFUL有以下特点:
1.每一个URI代表1种资源
2.客户端使用GET、POST、PUT、DELETE4个表示操作方式的动词对服务端资源进行操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源
3.通过操作资源的表现形式来操作资源
4.客户端与服务端之间的交互在请求之间是无状态的,从客户端到服务端的每个请求都必须包含理解请求所必需的信息
百度百科的解释总体来说还是有些学术化,一时让人不太好理解,笔者在知乎看到了一个比较通俗易懂的解释,短短几句话:
看url就知道要什么
看http method就知道干什么
看http status code就知道结果如何
比百度百科的解释更平易近人
声明:
任何可以用作css属性值的赋值都 可以用作sass的变量值
1 | $basic-border: 1px solid red; |
引用:
1 | .container { |
工作区、暂存区和版本库
工作区:
可直接在电脑上操作编辑的文件
暂存区:
数据暂时存放的区域
版本库:
存放已经提交的数据,使用push提交的时候,就是把这个区的数据push到远程git仓库了
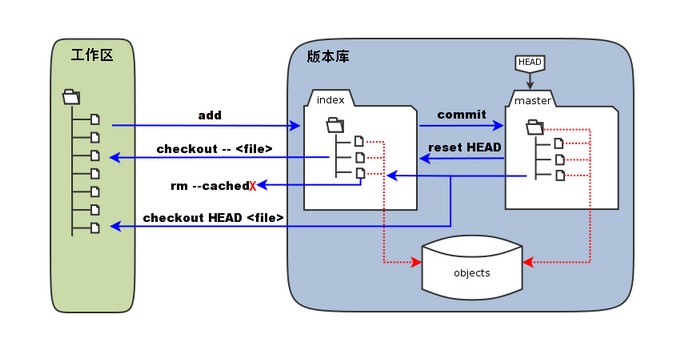
git clone
拷贝一份远程仓库
git init
初始化仓库
git add .
添加文件到暂存区
git commit -m ‘xxx’
将暂存区内容添加到仓库中
git push
上传远程代码并合并
git pull
下载远程代码并合并
git status
查看仓库当前的状态,显示有变更的文件
git diff
比较文件的不同,即暂存区和工作区的差异
git reset –hard git提交哈希值
回退到某一个版本
git branch -a
查看分支
git branch
查看当前分支
git branch <分支名称>
创建分支
git checkout <分支名称>
切换分支
合并分支:
git checkout master 先切换到master分支
git merge fenzhi 再将分支的代码合并到master
对Web应用的攻击模式有以下两种:
1.主动攻击
2.被动攻击
主动攻击:
攻击者通过直接访问Web应用,把攻击代码传入的攻击模式。由于该模式是直接针对服务器上的资源进行攻击,因此攻击者需要能够访问到那些资源。主动攻击模式里具有代表性的攻击是SQL注入攻击和OS命令注入攻击。
被动攻击:
利用圈套策略执行攻击代码的攻击模式。在被动攻击过程中,攻击者不直接对目标Web应用访问发起攻击。被动攻击模式中具有代表性的攻击是跨站脚本攻击和跨站点请求伪造。
跨站脚本攻击(XSS)
通过存在安全漏洞的Web网站注册用户的浏览器内运行非法的HTML标签或JavaScript进行的一种攻击。动态创建的HTML部分有可能隐藏着安全漏洞。就这样,攻击者编写脚本设下陷阱,用户在自己的浏览器上运行时,一不小心就会受到被动攻击。
影响:
1.利用虚假输入表单骗取用户信息
2.窃取用户Cookie,让用户在不知情的情况下帮助攻击者发送恶意请求
3.显示伪造的文章或图片
应对方法:
1.在Cookie中设置httpOnly,使js脚本无法读取到Cookie信息
2.过滤:
(1)对输入格式进行检查,前端和后端都要做
(2)对标签进行转换
(3)对特定字符进行转义处理
SQL注入攻击
针对Web应用使用的数据库,通过运行非法的SQL而产生的攻击。该安全隐患有可能引发极大的威胁,有时会直接导致个人信息及机密信息的泄露。
可能造成的影响:
1.非法查看或篡改数据库里的数据
2.规避认证
3.执行和数据库服务器业务关联的程序等
OS命令注入攻击
通过Web应用执行非法的操作系统命令达到攻击的目的。只要在能调用Shell函数的地方就有存在被攻击的风险。OS命令注入攻击可以向Shell发送命令,让Windows或Linux操作系统的命令行启动程序。也就是说,通过OS注入攻击可执行OS上安装着的各种程序。
跨站点请求伪造(CSRF)
攻击者通过设置好的陷阱,强制对已完成认证的用户进行非预期的个人信息或设定信息等某些状态更新,属于被动攻击。通俗来讲,就是攻击者冒充用户身份发起请求,在用户不知情的情况下完成一些违背用户意愿的事情
可能造成的影响:
1.利用已通过认证的用户权限更新设定信息等
2.利用已通过认证的用户权限购买商品
3.利用已通过认证的用户权限在留言版上发表言论
应对方法:
1.验证码
2.Token
3.Referer check 请求来源限制
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true